
| www.r-krell.de |
| Webangebot für Schule und Unterricht, Software, Fotovoltaik und mehr |
Willkommen/Übersicht > Informatik >
Teil 2: Entwurf, Normalisierung und Implementation
einschl. ER-Diagramm und SQL-Abfragen
Die Ausführungen über Datenbanken ergänzen meine Reihe „Informatik mit Java".
Auf der vorangegangenen Seite „Datenbanken, Teil 1" gab es die Übersicht und sinnvolle Software
Auf dieser Seite „Datenbanken, Teil 2" finden Sie:
Auf den folgenden Seiten kommt
- Datenbanken, Teil 3: Java und MySQL
...
zum Seitenanfang / zum Seitenende
Daten in Tabellen ('Relationen')
Ein Datenbank soll Daten so speichern, dass sie auf verschiedenste Art möglichst leicht ausgewertet und Antworten auf viele unterschiedliche Fragen gefunden werden können. Es reicht nicht, wenn man - wie etwa mit der (Volltext-)Suche auf einer Webseite - jedes Auftreten eines vorher einzugebenden Suchwortes findet. Es soll auch möglich sein, z.B. alle in der Datenbank gespeicherten Software-Produkte aufzulisten, auf Wunsch auch mit den jeweiligen Versionsbezeichnungen. Oder man soll den Gesamtbetrag erfragen können, der nötig ist, wenn man alle Software-Programme kaufen will. Oder es soll leicht möglich sein, sich die Anzahl der Programme nennen zu lassen, die beispielsweise zur Verbindung von Java und MySQL beitragen. Natürlich sollen bei einer anderen Anfrage auch die Programmnamen oder auch ihre Downloadquellen übersichtlich ausgegeben werden können. Damit dies möglich ist und der Computer bzw. das Datenbanksystem z.B. weiß, ob die irgendwo in der Datenbank auftauchende Zeichenfolge "8.25" eine Versionsnummer, der Euro-Betrag des Verkaufspreises, die Größe der Download-Datei in Megabyte oder noch etwas anderes ist, müssen die Daten strukturiert gespeichert werden. Für relationale Datenbanken wird dazu die Tabellenform verwendet, wobei Datenbanktabellen auch als Relation bezeichnet werden. Jeweils in eine Zeile schreibt man die zum gleichen Objekt oder Vorgang gehörenden Daten (man redet statt von der Zeile einer Tabelle auch von einem Datensatz oder einem Tupel der Relation), während gleichartige Eigenschaften (auch Attribute genannt) aller Objekte immer in den gleichen Spalten untereinander stehen:
Tabelle 'Beisp1'
Findet sich jetzt die "8.25" in der Spalte Version, so gilt sie als Versionsbezeichnung. In anderen Spalten würde sie entsprechend der Spaltenüberschrift (=Attributname) anders interpretiert.
Da - wie oben schon angedeutet - mit Fragen gezieltere Antworten erhalten werden sollen, als das normalerweise in einer Tabellenkalkulation möglich ist, benutzt man zur Verwaltung solcher Tabellen nicht Programme wie OpenOffice Calc oder MS Excel, sondern spezielle Datenbanksoftware wie etwa OpenOffice Base, MS Access, oder hier MySQL. Aber bevor wir auf programmtechnische Details eingehen, soll zunächst grundsätzlich untersucht werden, wie eine vernünftige Tabellen- bzw. Datenbankstruktur aussehen muss.
zum Seitenanfang / zum Seitenende
Normalisierung: Erste bis dritte Normalform
Wurden im ersten Beispiel gegenständliche Softwareprogramme in den Zeilen (Datensätzen, Tupeln) der Tabelle gespeichert, so gehört in der Schach-Tabelle jede Zeile zu einem Vorgang, nämlich zu einem Spiel.
zum Seitenanfang / zum Seitenende
1.) Von der nullten zur ersten Normalform
Tabelle 'Schach0'

Diese Tabelle ist allerdings noch nicht vernünftig strukturiert: Weil in den Spalten für den Leiter und die Spieler jeweils mehrere Informationen (nämlich Personenname, Vereinsname und Vereinsort) gemeinsam stehen, kann auf Einzelheiten nicht sicher zugegriffen werden. Deswegen soll die Tabelle verbessert, 'normalisiert' werden:
1. NF (erste Normalform): (a) Die Attribute müssen atomar sein, d.h. es dürfen nicht mehrere Informationen in einer Spalte stehen. (b) Außerdem dürfen nicht mehrere bedeutungsgleiche Spalten (sog. Wiederholungsgruppen) auftreten.
Beide Forderungen könnten hier durch Einführung weiterer Spalten realisiert werden:
Tabelle 'Schach1'

Dabei ist es etwas vom Kontext und der geplanten Verwendung der Datenbank abhängig, was als atomar gilt. Während hier das Datum nicht in Jahres-, Monats- und Tageszahl aufgeteilt wurde (weil es als eine Einheit angesehen wird und nicht erwartet wird, dass später nach den Einzelbestandteilen des Datums gefragt wird) und auch bei den Vereinsnamen verschiedene Wörter oder Namensbestandteile nicht in getrennte Spalten kamen (weil z.B. '1. SC Matt' als ein Vereinsnamen angesehen wird), wurde das Ergebnis auf 2 Spalten verteilt - weil erwartet wird, dass man sich vielleicht später für die von einem Spieler errungenen Punkte interessieren könnte.
Auch wenn jetzt drei Spalten für Personennamen, drei Spalten für Vereinsnamen und drei Spalten für Vereinsorte sowie zwei Spalten für Punkte eingerichtet wurden, sind keine unzulässigen Wiederholungsgruppen entstanden: Die Inhalte sind nicht austauschbar, d.h. ob '2' als Punkte1 oder als Punkte2 eingetragen werden, macht einen Unterschied. Anders wäre es bei ungeordneten Angaben: Hätte z.B. eine Person ihre Hobbys als 'Reiten, Lesen, Tanzen, Musikhören' angegeben, ohne(!) damit eine bestimmte Rangfolge ausdrücken zu wollen, dürften nicht einfach vier Hobby-Spalten eingerichtet und die Hobbys irgendwie verteilt werden: Dann würde man von einer unerlaubten Wiederholungsgruppe der Hobbys ausgehen und die Spaltenüberschriften 'Hobby1', 'Hobby2', .. 'Hobby4' als willkürlich empfinden. Im Schachbeispiel unterscheiden sich hingegen Spieler1 und Spieler2 durch die Figurenfarbe und damit den Spielbeginn, was für Spielverlauf und Ergebnis durchaus wichtig sein kann. Und der Leiter hat eine andere Funktion als die Spieler. Also handelt es sich in der gezeigten Tabelle Schach1 nicht um eine Wiederholung gleichwertiger Spalten mit austauschbaren Personennamen, sondern die erste Normalform ist erfüllt.
zum Seitenanfang / zum Seitenende
2.) Von der ersten zur zweiten Normalform
Trotz Normalisierung entsprechend der 1. NF ist die oben gezeigte Tabelle Schach1 immer noch nicht wirklich gut: Viele Informationen sind unnötigerweise mehrfach eingetragen, was neben zu viel Eingabearbeit und Speicherplatzverschwendung das Risiko birgt, dass Inkonsistenzen oder Widersprüche auftreten - beispielsweise wenn beim Spieler Kerkhoff einmal versehentlich als Vereinsort des 1. SC Matt eine andere Stadt, etwa Köln, angegeben würde: zu welchem Verein gehört Kerkhoff dann, zum 1. SC Matt aus Köln (wie dann in Zeile 2) oder zum 1. SC Matt aus Düsseldorf (wie weiter in Zeile 5)? Wobei wir davon ausgehen, dass es nicht zufällig zwei namensgleiche Spieler Kerkhoff aus zufällig gleichnamigen Vereinen in verschiedenen Städten geben soll, sondern es sich nach wie vor um die eine Spielerin oder den einen Spieler Kerkhoff handelt, der/die bisher schon unsere Tabellen bevölkert hat.
Am besten sollen alle Informationen daher nur genau einmal in einer Datenbank stehen. Man vermeidet also Redundanzen und damit allerdings auch Kontrollmöglichkeiten: Hätte ein Eingabefehler beim mehrfach enthaltenen Ort bisher zu einem Widerspruch geführt und dadurch Anlass gegeben, den Vereinsort nochmal anderweitig nachzuprüfen, so hat die Fehleingabe ohne Doppelungen insofern fatalere Folgen, weil die Datenbank trotzdem konsistent und formal richtig bleibt. Der Fehler würde nicht ohne Weiteres erkannt. Es ist also künftig mehr Sorgfalt bei der Eingabe erforderlich. Außerdem muss man die Daten jetzt meist auf mehrere Tabellen aufteilen.
2. NF (zweite Normalform): (a) Alle Datensätze müssen einen eindeutigen (Primär-)Schlüssel haben, d.h. in einer Spalte oder in einer Kombination aus mehreren Spalten muss jedes Tupel einen Wert oder eine Wertekombination haben ('Schlüsselattribute'), der/die nur in dieser Zeile auftritt und den Datensatz eindeutig identifiziert. (b) Alle anderen (Nicht-Schlüssel-) Attribute hängen voll funktional von allen Schlüsselattributen gemeinsam ab (und - bei mehreren Schlüsselattributen - nicht nur von einem Teil des Schlüssels). (c) Außerdem muss weiterhin die 1. NF erfüllt sein.
Im Beispiel kann die Spielnummer als eindeutiger Primärschlüssel verwendet werden: Die Nummern aller Spiele (1 Spiel = 1 Zeile = 1 Tupel = 1 Datensatz) unterscheiden sich. Hingegen gäbe das Attribut Leiter keinen Primärschlüssel ab: mehrere Spiele werden unter gleicher Leitung abgehalten. Aber die Kombination aus Leiter und Spieler1 (oder auch aus Datum, Spieler1 und Spieler2) hätte jeweils als zusammengesetzter Schlüssel dienen können, weil die eingetragenen Wertekombinationen in diesen Spalten gemeinsam ebenfalls eindeutig sind. Der Einfachheit halber soll aber die Spielnummer als einfacher Schlüssel gewählt werden. Nun hängt natürlich der Vereinsort L_VOrt des Spielleiters keineswegs vom Primärschlüssel ab: Ganz egal, ob es sich um das erste, dritte, vierte oder sechste Spiel handelt: Leiter Meier hat immer den Vereinsort Düsseldorf, egal, wie sich die Spielnummer ändert. Ebenso geht es natürlich auch mit der Vereinszugehörigkeit von Leiter und Spielern: auch sie hängt nicht von der Spielnummer ab, sondern besteht unabhängig von der Spielnummer. Das bedeutet aber, dass diese Vereinszugehörigkeiten und -orte nicht mehr in der Spiele-Tabelle mit den nummerierten Spielen eingetragen werden dürfen, sondern in eigene Tabellen ausgelagert werden müssen. Geht man (wie oben bereits erwähnt) davon aus, dass es weder bei Vereinen noch bei Spielern verschiedene Objekte gleichen Namens gibt, müssen folgende drei Tabellen angelegt werden, die gemeinsam die Datenbank oder Datenbasis bilden:
'Schach2'
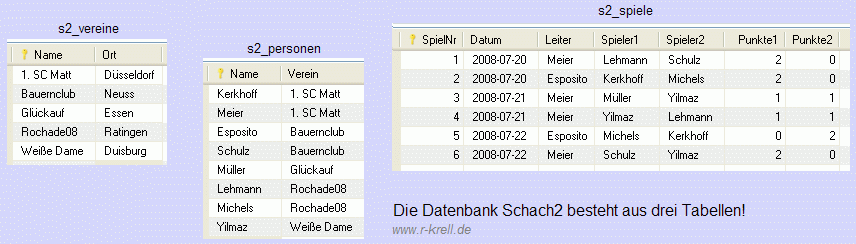
Als erstes wird die Vereinstabelle angelegt, weil die hier eingetragenen Daten am längsten Bestand haben: Vereine sind für Jahrzehnte gegründet und wechseln ihren Vereinsort selten. Dann kommen die Mitglieder bzw. Personen, die meist jahrelang in ihrem Verein bleiben. Zum Schluss wird die Spieltabelle angelegt: Spiele sind häufig; an vielen verschiedenen Tagen werden immer wieder unterschiedliche Spiele mit wechselnden Besetzungen und Ergebnissen durchgeführt.
In allen drei Tabellen wurde die jeweils erste Spalte als Primärschlüssel gewählt (gelbes Ausrufezeichen im Tabellenkopf), weil die Einträge in diesen Spalten eindeutig sind und nirgends zwei Zeilen mit gleichen Werten in der ersten Spalte vorkommen. Damit ist Forderung (a) der 2. NF überall erfüllt. (Ebenso hätte man auch eindeutige Vereins- und Mitgliedsnummern vergeben können und diese zu den Primärschlüsseln gemacht. Das ist aber keineswegs nötig).
Offensichtlich ist außerdem die Forderung (b) der 2. NF für die beiden 2-spaltigen Tabellen erfüllt: Natürlich hängt der Vereinsort vom Verein ab und die Mitgliedschaft einer Person in einem Verein von der Person. In der Tabelle s2_spiele finden sich hingegen sechs Nicht-Schlüssel-Attribute: Hängen sie wirklich alle vom Spiel ab (gekennzeichnet durch eine willkürlich, aber eindeutig vergebene Spielnummer)? Da Spiele an verschiedenen Tagen, unter verschiedenen Leitern, mit unterschiedlichen Spielerpaarungen und mit wechselnden Ergebnissen stattfinden können, sind tatsächlich alle diese Daten für ein Spiel wichtig und beschreiben das Spiel. Das Ergebnis hängt auch nicht etwa nur von den beiden Spielern ab (statt vom Spiel selbst): Treffen die gleichen Spieler in einem anderen Spiel wieder aufeinander, so kann das Ergebnis ganz anders aussehen! Tatsächlich sind hier wirklich alle Attribute 'voll funktional' vom Spiel abhängig bzw. zum Spiel gehörig - auch s2_spiele erfüllt Teil (b) der 2. NF und damit genügt die ganze Datenbank Schach2 der zweiten Normalform.
Übrigens war es tatsächlich nötig, für diese Normalisierung drei Tabellen einzurichten - zwei hätten nicht gereicht: So ist es nicht möglich, um etwa die Tabelle s2_vereine einzusparen, die Vereinsorte einfach als dritte Spalte an die Tabelle s2_personen anzuhängen. Denn die Vereinsorte sind nicht vom Mitglied abhängig: es ist egal, ob Kerkhoff, Meier oder jemand anderes Mitglied im 1. SC Matt ist: der Vereinsort des 1. SC Matt ist immer Düsseldorf. Wenn der Vereinsort aber nicht von der Person des Mitglieds abhängig ist, darf der Ort nicht in der Personentabelle stehen, deren Primärschlüssel jeweils eine Person namentlich kennzeichnet. Vielmehr muss der Vereinsort in eine andere Tabelle als die Personen und die Spiele, weswegen s2_vereine wirklich benötig wurde!
Die ursprünglich in einer Tabelle stehenden Informationen sind durch die vorgenommene Normalisierung, d.h. die Anpassung an die 2. NF, jetzt allerdings über mehrere Tabellen verteilt. Damit auch jetzt wieder alle Informationen gefunden werden können, die in Schach0 und Schach1 enthalten waren, müssen die drei Tabellen der neuen Datenbank Schach2 aber immer auch inhaltlich zusammen passen: Jede Person, die als Leiter, Spieler1 oder Spieler2 in der Tabelle s2_spiele eingetragen ist, muss schon in der (deswegen zuvor zu füllenden) Tabelle s2_personen vorkommen und dort einem Verein zugeordnet sein. Und jeder Verein, der in der zweiten Spalte von s2_personen steht, muss bereits in der allerersten Tabelle s2_vereine zu finden sein und dort einen Ort haben. Andernfalls wären Zusammenhänge gestört und Verweise von einer Tabelle zur anderen wären unterbrochen: die sogenannte Referenzintegrität wäre gestört.
Von vernünftigen Datenbankprogrammen wird erwartet, dass sie die referenzielle Integrität auf Wunsch überwachen können und für die Tabellen s2_spiele und s2_personen nur solche Eintragungen zulassen, zu denen es bereits passende Datensätze in s2_personen bzw. s2_vereine gibt - weswegen beim Füllen mit Daten auch mit der Tabelle s2_vereine angefangen werden muss, die ihrerseits keine Bezüge (Fremdschlüssel) zu anderen Tabellen enthält. Außerdem muss im Interesse der Referenzintegrität verhindert werden, dass man etwa aus der Tabelle s2_vereine einen Verein löschen kann, solange in der Tabelle s2_personen noch Mitglieder dieses Vereins zu finden sind. Sie würden sonst plötzlich heimatlos.
zum Seitenanfang / zum Seitenende
3.) Von der zweiten zur dritten Normalform
Die 3. NF verschärft das Ziel, zu jedem 'Thema' eine eigene Tabelle zu erzwingen. Die Tabellen sollen noch weniger Spalten haben, die noch strenger vom Schlüsselattribut - oder bei mehrspaltigen Schlüsseln: von allen Schlüsselattributen gemeinsam und nicht etwa nur von einigen Schlüsselattributen - abhängen. Wieder ist die 3. NF eine Verschärfung der vorhergehenden 2. NF, die ebenfalls weiterhin erfüllt sein muss.
3. NF (dritte Normalform): (a) Die Datenbank (= das Relationenschema) erfüllt die 2. NF; (b) Alle Nichtschlüsselattribute jeder Tabelle (= jeder Relation) hängen vom gesamten (Primär-)Schlüssel dieser Tabelle unmittelbar ab und hängen von keinem Schlüsselattribut nur transitiv (indirekt) ab.
Die oben genannte Datenbank Schach2 erfüllt bereits die 3. NF: Würde hingegen z.B. der Leiter
eines Spiels nur vom Datum abhängen (am 20.7. und 21.7. leitet Meier alle Spiele, am 22.7. kommt Esposito dran),
dann wäre höchstens eine indirekte (mittelbare) Abhängigkeit des Leiters vom Spiel bzw. der
Spielnummer gegeben: Jedes Spiel findet an einem bestimmten Tag statt und davon hinge dann ab, wer der Leiter ist.
Das wäre eine transitive Abhängigkeit, die durch eine weitere Tabelle aufgelöst werden müsste:
Die Leiterspalte würde aus s2_spiele verschwinden und eine vierte Tabelle s3_leiter würde
die Zuordnung zwischen Datum und Leiter beinhalten.
Aber im Beispiel gibt es die reine Datumsabhängigkeit nicht: Der Leiter hängt insofern doch direkt vom
Spiel ab, als man offenbar vermeiden will, dass ein Spiel von einem Vereinskameraden eines der Spieler geleitet wird.
Und auch wenn oben am 21.7. immer Meier leitet, zeigen die anderen Tage, dass die Datumsangabe zur Ermittlung des
Leiters nicht ausreicht. Die 3. NF ist hier wirklich schon erfüllt.
Ein anderes Beispiel für Unterschiede zwischen der 2. NF und der 3. NF gibt es bei den häufig verwendeten Adresstabellen. Nach der 3. NF darf die Postleitzahl (PLZ) einer Person nicht in der gleichen Tabelle wie ihr Name und der Rest der Anschrift gespeichert werden. Denn die PLZ hängt nicht von der Person ab, die an einer bestimmten Adresse wohnt, sondern lässt sich allein aus der Kombination aus Wohnort, Straße und Hausnummer ermitteln (z.B. aus dem PLZ-Verzeichnis, das keine Personenangaben enthält. Bei kleinen Gemeinden reicht schon der Ort für die PLZ; in Großstädten wechselt die PLZ hingen manchmal längs einer Straße). Die PLZ hängt also nur indirekt (transitiv) von der Person (und dem zur Kennzeichnung der Person verwendeten Schlüssel) ab, aber direkt von Wohnort, Straße und Hausnummer. Die PLZ müsste daher in eine Extratabelle, die dem PLZ-Verzeichnis (oder dem davon benötigten Ausschnitt) entspricht. Im Alltag verzichtet man aber oft auf die strenge Anwendung der 3.NF und insbesondere auf weitere, höhere und hier nicht behandelte Normalformen, die zu immer mehr Tabellen in einer Datenbank führen.
Besteht der Primärschlüssel einer Tabelle aus einer Kombination von mehreren Attributen, so kann die Prüfung auf 2. und 3. NF durchaus anstrengend werden, um Teilabhängigkeiten auszuschließen. In der Praxis führt man zur Vermeidung zusammengesetzter Schlüssel oft künstlich geschaffene eindeutige Identitätskennzeichen (Personalnummern, Mitgliedsnummern, Vorgangsnummern, usw.) ein, wie wir es ja auch schon mit den Spielnummern getan haben.
Mehr zu Normalformen gibt's u.a. bei Wikipedia: http://de.wikipedia.org/wiki/Normalisierung_(Datenbank) (zumindest Anfang August 2008).
zum Seitenanfang / zum Seitenende
Vermeidung von Anomalien
durch Normalisierung und Referenzintegrität
Bei den vorstehenden Ausführungen zur 3. NF war schon von der Referenzintegrität die Rede, damit die verschiedenen Tabellen einer Datenbank auch zusammen passen. Insbesondere in der etwas älteren Literatur wird häufig vor drei Problemen ('Anomalien') gewarnt, die bei ungeschickter Tabellenaufteilung und/oder fehlender Referenzintegrität auftreten können:
Angenommen, in einer Schule führen die Lehrerinnen und Lehrer aller Fächer jeweils eigene Klassenlisten, wobei sie neben den Namen auch jeweils die Telefonnummern der Eltern ihrer Schülerinnen und Schüler notieren, um in Notfällen oder zu pädagogischen Beratungen direkt anrufen zu können. Nachdem im Lehrerzimmer ein Computer aufgestellt wird, tippen alle Lehrer ihre Listen dort ein. Die Gesamtheit dieser Fach-Listen (die ja letztlich Tabellen ['Relationen'] mit den Spalten ['Attributen'] Namen, Vornamen und Elterntelefonnummer sind) bilden eine Datenbank.
Um die Redundanz zu verringern, beschließen die Lehrer, dass die Telefonnummern nur noch bei einem Fach gespeichert werden (und die anderen Lehrer im Bedarfsfall dort nachgucken). Weil die Englischlehrerin besonders zuverlässig ist und jede Schülerin und jeder Schüler ja eine erste Fremdsprache haben muss, sollen die Telefonnummern nur noch in der Liste für die erste Fremdsprache gespeichert werden.
Das Risiko dieser Anomalien beseitigt man im Beispiel am besten, in dem man eine fachunabhängige Schülertabelle für die Stammdaten aus Vor- und Zunamen und allen Telefonnummern anlegt und als (Primär-)Schlüssel eine eindeutige Schülernummer vergibt. In den Tabellen der einzelnen Fächern steht dann nur die Schülernummer (als Fremdschlüssel, also als Verweis auf den Schüler und seine Daten in der Stammdaten-Tabelle). Man sollte bei strenger Normalisierung in den Fachtabellen tatsächlich völlig auf ausgeschriebene Vor- und Zunamen verzichten, denn sonst könnten bei Namensänderungen wieder Probleme auftreten...
Auch in der Schach-Datenbank aus dem vorangehenden Kapitel können die drei Anomalien auftreten: Bis einschl. der ersten Normalform wären z.B. bei Vereinswechsel eines Spielers oder Leiters wegen der Mehrfachspeicherung Änderungsanomalien möglich, wenn die Änderung nicht an jeder Stelle gelingt. Will man die Datenbank auch als Mitgliederliste verwenden, dann lassen sich in Schach0 oder Schach1 nur solche Spieler und Leiter speichern, die am Turnier teilnehmen - andere Spieler können nicht eingefügt werden (Einfügeanomalie). Oder bereits gespeicherte Namen und Vereinszugehörigkeiten gingen bei Streichung eines ausgefallenen oder nachträglich wegen entdeckter Unregelmäßigkeiten gestrichenen Spiels verloren (Löschanomalie). Vor Anomalien bewahrt die Normalisierung mit vernünftiger Tabellenaufteilung: In Schach2 sind weder die Änderungs- noch die Einfügeanomalie mehr möglich, da Redundanz vermieden wird und in die Tabellen s2_vereine und s2_personen durchaus Vereine und Schachspieler eingefügt werden können, die nicht an dem in s2_spiele beschriebenen Turnier teilnehmen/teilgenommen haben. Ein Problem könnte sich höchstens beim langfristigem Speichern alter Spiele ergeben: Wird immer nur die Tabelle s2_spiele von den Turnieren lange zurückliegender Jahre aufbewahrt, während die anderen Tabellen aktualisiert werden, würde man nach Jahren die Vereinszugehörigkeit von inzwischen aus dem Verein ausgeschiedenen Spielern nicht mehr rekonstruieren können (Löschanomalie). Lässt man allerdings die Datenbanksoftware die Referenzintegrität überwachen, so sollte ein solches Löschen nicht möglich sein.
Weitere Beispiele und Ausführungen zu Anomalien gibt's (auch im Oktober 2009) u.a. bei http://de.wikipedia.org/wiki/Anomalie_(Informatik)
zum Seitenanfang / zum Seitenende
Datenbankentwurf:
grafische Modellierungshilfen und Veranschaulichung
der Zusammenhänge zwischen Tabellen
Das Erstellen einer guten Datenbank ist nicht einfach. Zunächst muss man herausfinden, welche Eigenschaften, Zusammenhänge und Vorgänge überhaupt interessieren (d.h. wie die Wirklichkeit modelliert werden soll) und dafür müssen passende Tabellen mit sinnvollen Attributen für die 2. oder 3. NF eingerichtet werden. Zur Vereinfachung des Datenbankentwurfs oder auch nur, um anschließend die Zusammenhänge zwischen den aufgestellten Tabellen nicht zu vergessen, gibt es verschiedene Hilfsmittel:
zum Seitenanfang / zum Seitenende
Tabellenköpfe mit Pfeilen
In einem einfachen Tabellenschema werden mindestens die Tabellenamen und alle Spaltenüberschriften notiert. Zu den Spalten kann man hinzufügen, welche Art Daten eingetragen werden sollen und/oder zur Veranschaulichung der Inhalte am besten auch eine oder einige Beispielzeilen eintragen. Primärschlüssel werden unterstrichen, Fremdschlüsseln wird ein Pfeil vorangestellt. Besonders anschaulich wird's, wenn die mit den Fremdschlüsseln geplanten Verbindungen als Pfeile gezeichnet werden, sodass man sich entlang der Pfeile zu den weiteren Informationen hangeln kann. Für Schach2 (wie oben dargestellt) sähe das etwa so aus:

zum Seitenanfang / zum Seitenende
Entity-Relationship-Diagramm (ERD)
Im ER-Diagramm werden dargestellt
Unter Ganzheiten kann man sich reale Objekte (Personen, Vereine) aber auch Vorgänge (Spiele) oder direkt Tabellen vorstellen, während die Beziehungen im Wesentlichen die oben durch Pfeile veranschaulichten Zusammenhänge zwischen den Tabellen sind. Allerdings werden - wie später noch deutlich wird - auch für manche Beziehungen zusätzliche Tabellen gebraucht. Für Schach2 scheint das ER-Diagramm nicht schwer zu sein. Hier wurde es mit dem bereits auf meiner Seite „Objektorientierte Anwendungsentwicklung und Software-Engineering" vorgestellten kostenlosen Programm 'Diagram Designer' von Meesoft erstellt:
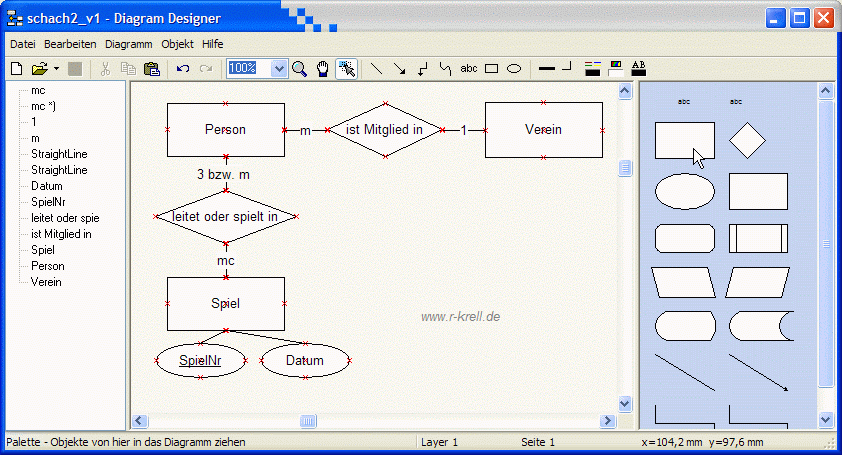
Zusätzlich wurden an/in die Beziehungslinien noch Multiplizitäten eingetragen: Jede Person ist Mitglied in genau einem Verein (1), während ein Verein immer mehrere Personen (m) als Mitglieder zählt. Jede Person kann an keinem, an einem (0..1 = c) oder an mehreren (m) Spielen teilnehmen (insgesamt also mc), während pro Spiel immer drei Personen beteiligt sind. In der modifizierten Chen-Notation für die Multiplizitäten würde aber statt der exakten 3 nur etwas ungenauer ein m für „mehrere" notiert, da nur die Zeichen 1, c (=0 oder 1) und m (1..n) zugelassen sind -- wobei für 0..n die Kombination mc verwendet wird. Andere Zahlen oder Zeichen(-kombinationen) sind in der modifizierten Chen-Notation nicht vorgesehen, im Alltag oder Unterricht aber durchaus hilfreich.
Um die unterschiedlichen Rollen, die eine Person im Spiel einnehmen kann, deutlicher zu machen, sind sogar besser drei statt einer Beziehung zwischen Person und Spiel sinnvoll:
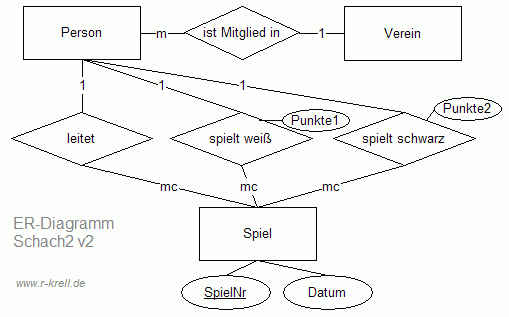
Nur bei m(c):m(c)-Beziehungen gelingt es unter Einhaltung der 2. NF nicht, die Verbindung durch eine
zusätzliche Spalte in einer bereits vorhandenen Tabelle herzustellen. Bei 1:m(c)- oder
c:m(c)-Beziehungen geht das hingegen: Dort kann man immer in der Tabelle auf der m-Seite eine
Spalte anfügen, um durch einen Eintrag in dieser Spalte auf den einen zugehörigen Datensatz in der anderen
Tabelle (auf deren Seite die Multiplizität 1 steht) zu verweisen. Umgekehrt geht's nicht: Aus der
1-er Tabelle müsste man ja auf mehrere Einträge in der m-Tabelle verweisen, was nur durch
mehrere Werte (und damit durch Verstoß gegen die erste Normalform mit dem Gebot zu atomaren Einträgen und
dem Verbot von mehreren Spalten für gleichwertige Einträge) erreicht werden könnte. Also ist bei
m:m-Beziehungen eine eigene Tabelle für die Beziehung nötig, in der -- immer ein Paar pro Zeile --
alle Paare mit den zwei Verweisen auf die in Beziehung stehenden Datensätze aus den beiden durch die Beziehung
verknüpften Tabellen stehen.
Auch deshalb ist das zweite ER-Diagramm ("Schach2 v2") mit den drei 1:mc-Beziehungen zwischen Person(en) und
Spiel besser als die erste Version, weil die zweite Version die aufwändig mit einer weiteren Tabelle zu
modellierende m:mc-Beziehung des ersten Entwurfs vermeidet! Bei der 'ist Mitglied in'-Beziehung ist
übrigens, wie gerade erläutert, auf der m-Seite, also in der Personen-Tabelle
s2_personen, eine Spalte für den Fremdschlüssel mit dem jeweils einen (1) Vereinsnamen
pro Person enthalten.
Das Attribut für den Ort in der s2_vereine-Tabelle hätte im ERD noch durch eine Ellipse an der
'Ganzheit' (Entität) Verein verdeutlicht werden können, da sich der Ort nicht aus den eingezeichneten
Beziehungen ergibt.
Das ER-Diagramm kann für den Datenbankentwurf also schon verwendet werden, wenn man sich noch mehr an den zu modellierenden Objekten (Ganzheiten) der Wirklichkeit orientiert und noch keine klare Vorstellung von den anzulegenden Tabellen hat. Die notwendigen Tabellen können nachher unter Beachtung der Multiplizitäten aus dem ERD abgeleitet werden.
Statt der oben - entsprechend den Anforderungen des Zentralabiturs - verwendeten modifizierten Chen-Notation für die Multiplizitäten ist es natürlich auch möglich, im ER-Diagramm jede andere Notation zu verwenden. Sinnvoll dürfte es sein, auch hier die Multiplizitäten auf die gleiche Art zu kennzeichnen, wie das bisher im Unterricht - etwa im UML-Klassendiagramm - geschah: z.B. mit 0, 1 und * (für viele) (vgl. meine Seite „Objektorientierte Anwendungsentwicklung und Software-Engineering")
zum Seitenanfang / zum Seitenende
Implementation der Schachdatenbank in MySQL
Die im letzten Kapitel angesprochenen grafischen Methoden helfen beim Datenbankentwurf. Die Realisierung der Datenbank im Computer und die anschließenden Arbeit mit der Datenbank ist trotzdem der entscheidende Test, ob die Modellierung gelungen ist. Da eine nachträgliche Änderung der Tabellen und die damit verbundene Änderung oder Neueingabe vieler Daten in der Praxis allerdings nur mit sehr viel Aufwand möglich ist, kann ein trial-&-error-Verfahren (wie etwa beim Austesten von Programmzeilen beim quick&dirty-Entwurf kurzer Programme) hier nicht empfohlen werden. Der Implementation muss unbedingt eine sorgfältige Modellierung voraus gehen!
Ist wirklich klar, welche Tabellen angelegt werden sollen (beispielsweise die der Datenbank Schach2), kann dies nun in der Datenbanksoftware geschehen. Hier wird MySQL mit dem QueryBrowser benutzt - zu Installation und Start vergleiche meine Anleitung im Teil 1 meiner Ausführungen über Datenbanken.
zum Seitenanfang / zum Seitenende
Wichtige Sprachelemente von SQL
Viele Datenbankmanagementsysteme bieten mehrere Möglichkeiten an, wie Datenbanken und Tabellen erzeugt werden können. Praktisch alle erlauben die Verwendung der Sprache SQL. Die wichtigsten Befehle sind hier zusammengestellt. Das unten nur verkleinert abgebildete Arbeitsblatt kann durch Klick ins Bild in einem eigenen Fenster als pdf-Datei geöffnet bzw. herunter geladen werden (23 kB):

Die Befehle sollen nun zum Anlegen und Füllen unserer Datenbank eingesetzt werden.
zum Seitenanfang / zum Seitenende
Erzeugen und Füllen der Datenbank mit SQL-Anweisungen
In den QueryBrowser können nacheinander die benötigten Befehle eingegeben werden, die jeweils mit einem Semikolon abgeschlossen werden müssen. Die Befehle können dabei durchaus über mehrere Zeilen gehen; der QueryBrowser merkt am Semikolon, wo ein Befehl aufhört und setzt einen dicken Punkt vor den Anfang. Um einen eingegebenen Befehl tatsächlich auch auszuführen, muss der Kursor (die Schreibmarke) irgendwo in den Befehl platziert werden und entweder die Strg- und die Eingabetaste gleichzeitig gedrückt oder die „Die eingegebene Abfrage ausführen"-Schaltfläche (weißer Blitz in grünem Kreis) angeklickt werden. Ganz unten kommt dann eine Erfolgs- oder Fehlermeldung, wobei die Erfolgsmeldung durchaus „Abfrage erzeugt keine Ergebnismenge" lauten kann!
Die hier erforderlichen und geeigneten Befehle werden direkt im QueryBrowser gezeigt. Alle Anweisungen wurden in der eingegebenen Reihenfolge ausgeführt; das Bild zeigt den Bildschirm nach Ausführung des letzten, fünften Befehls (in Zeile 13):
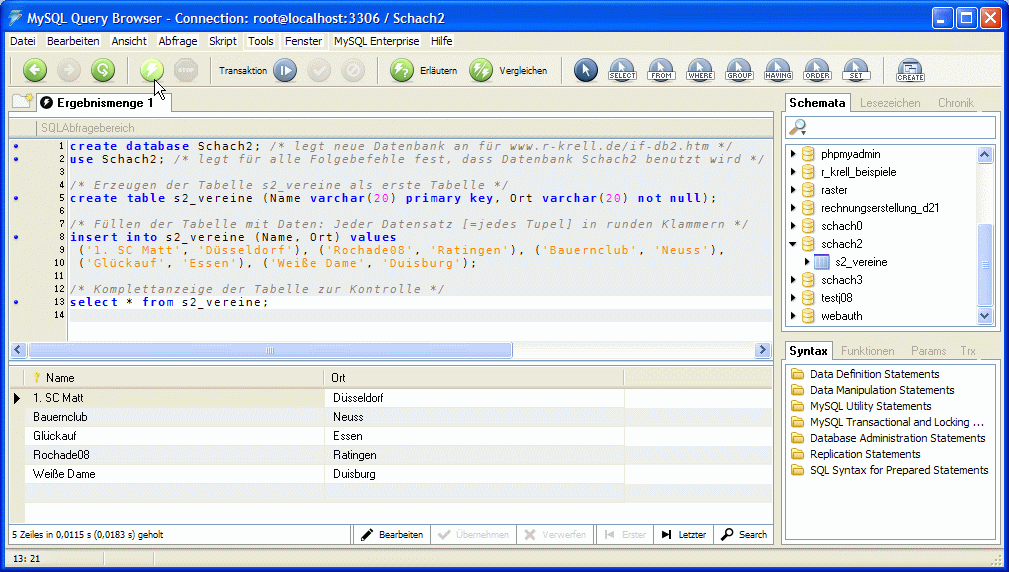
Der Zusatz „not null" hinter dem Ort verhindert, dass bei der Eingabe eines Vereins der Ort weggelassen werden kann. Beim Vereinsnamen verhindert bereits die Kennzeichnung als „primary key" (Primärschlüssel) eine leere Eingabe. Die Datensätze können einzeln oder wie hier mit einem gemeinsamen insert-Befehl angegeben werden.
Wurde die Tabelle s2_vereine erstellt, so können anschließend auch die Tabellen erstellt und gefüllt werden, die sich darauf beziehen. Zunächst wird s2_peronen angelegt und gefüllt. Der Zusatz „foreign key (Verein).." erklärt den Verein zum Fremdschlüssel und lässt bei der Eingabe bzw. beim insert-Befehl nur solche Vereinsnamen zu, die bereits in der oben erzeugten Tabelle s2_vereine stehen. Bitte probieren Sie aus, dass eine andere Eingabe zu einer Fehlermeldung führt - vorausgesetzt, Sie haben wie im Teil 1 beschrieben die InnoDB eingeschaltet!
|
/* Schach2 - Befehle 6 bis 8: Erzeugen, Füllen und Anzeigen der Tabelle s2_personen */
create table s2_personen (Name varchar(20) primary
key, Verein varchar(20), insert into s2_personen (Name, Verein) select * from s2_personen; |
Ebenso lässt sich jetzt die letzte Tabelle s2_spiele erstellen. Die Anzeige nach Ausführung der select-Anweisung sollte - nachdem man die Spaltenbreiten mit der Maus etwas verringert hat - dem Bild aus dem ersten Kapitel entsprechen!
|
/* Schach2 - Befehle 9 bis 11: Erzeugen, Füllen und Anzeigen der Tabelle s2_spiele */
create table s2_spiele (SpielNr int primary key,
Datum date, Leiter varchar(20), insert into s2_spiele (SpielNr, Datum, Leiter,
Spieler1, Spieler2, Punkte1, Punkte2) select * from s2_spiele; |
Damit ist die Datenbank erfolgreich eingegeben. Haben Sie Fehler gemacht, müssen Sie falsch angefangene Tabellen erst mit dem drop-Befehl löschen, bevor Sie sie erneut erzeugen können - alternativ können Fehler auch mit dem alter- oder update-Befehl verändert werden (wie im obigen Arbeitsblatt angegeben).
zum Seitenanfang / zum Seitenende
Einige select-Abfragen in der Schachdatenbank
Um die Tauglichkeit der Datenbank zu erfahren, sollen einige willkürlich zusammen gestellte Abfragen im QueryBrowser eingegeben und ausgeführt werden, um so die Arbeit mit der Datenbank zu demonstrieren. Natürlich lernt man die geschickte Nutzung der Sprache SQL nur durch Üben und eigenes Probieren an immer wieder neuen Beispielen und Fragestellungen. Die nachfolgend willkürlich gestellten 19 Fragen können nur eine erste Anregung sein. Am besten sehen Sie sich meine Lösungen erst an, nachdem Sie jeweils selbst überlegt haben. Oft gibt es auch mehrere Möglichkeiten, sodass das Ausprobieren im QueryBrowser auch die Richtigkeit anderer Ideen bestätigen kann. Die Fragen wurden hier immer mehrzeilig geschrieben, die Verteilung auf verschiedene Zeilen dient der Übersichtlichkeit, ist aber für das Ergebnis bzw. für den QueryBrowser egal!
Vorausgesetzt wird, dass die Datenbank Schach2 wie vorstehend beschrieben angelegt wurde. Sie bleibt dann auch für folgende/künftige Sitzungen auf Ihrem Computer. Wenn Sie eine neue Sitzung beginnen starten, sollten Sie zunächst use schach2; eingeben, damit auch die richtige, oben erstellte Datenbank benutzt wird!
Zunächst wird nur mit einer Tabelle, z.B. nur mit s2_spiele, gearbeitet:
Abfragen zur Verknüpfung mehrerer Tabellen (Join), hier zunächst von zwei Tabellen:
wobei das folgende Beispiel zeigt, dass nicht nur über ausgewiesene Fremdschlüssel bzw. in Richtung der Referenzpfeile verknüpft werden kann (die Angabe von Fremdschlüsseln dient der Überwachung der Referenzintegrität bei Eingabe und Änderung und ist fürs Fragen egal!):
Und schließlich Verknüpfungen über alle drei Tabellen, wobei hier jeweils nur eine Methode (die oben als 'Methode 2' bezeichnete Variante mit Kommaschreibweise) angegeben ist, aber natürlich auch die anderen Methoden möglich sind:
Will man nun auch die Spieler einbeziehen, muss mehrfach in der Personen- und in der Vereinstabelle nachgesehen werden. Um Missverständnisse zu vermeiden, erhalten die Tabellen beliebige aber verschiedene Alias-Namen:
Und zum Schluss (sozusagen als Beweis, das wirklich noch alle Informationen aus Schach0 in Schach2 stecken:)
Gerade die letzten Abfragen sollten ausprobiert werden und sind nicht ganz trivial!
zurück zur Informatik-Hauptseite
zur vorangehenden Seite: Datenbanken, Teil 1
oder zur nächsten Seite: Datenbanken, Teil 3